Event Sourcing and CQRS: Learning points
Event sourcing and CQRS are two very powerful event-driven patterns. They can work independently but in this post, I am going to explain my own experience working with both patterns together. There are plenty of resources online around Event Sourcing and CQRS (please check the links at the end of the page for further information). Here is just a brief description:
- Event Sourcing: Is an architectural pattern where every change in an application is captured as an event. Event Sourcing persists the state of a business entity as a sequence of state-changing events.
- CQRS: Stands for Command Query Responsibility Segregation where you separate update operations from reading operations to a data store.
Benefits of Event Sourcing:
- Auditability: Every single action in your application is recorded.
- Reproducibility: You can reproduce the state of your application by replaying the events.
- Historic State: For any given point in time you will be able to query the state of your application.
Benefits of CQRS:
- Scalability: You can scale write and read operations independently. Especially useful if you have systems that take a long time processing update requests.
- Enforce recording every event: Every action is actually recorded, because any write operation needs to be published to the read side.
The last point was the main reason to apply CQRS in my last project. Every command will produce an event that will contain all the data that your view will need. Therefore, if you have a new service that is going to consume already published events, then it will be able to consume all the events from the beginning and no data will be missing.
Sample Case
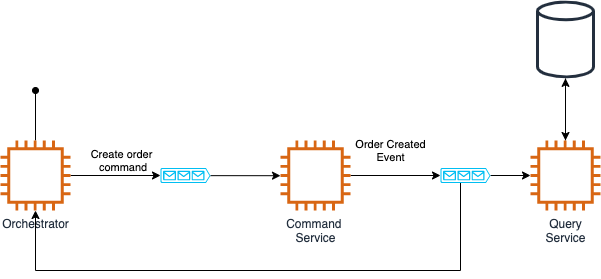
The above diagram shows a sample of an Event Sourcing + CQRS architecture I worked with. Where usually you have 1 microservice in charge of one particular domain model, now this has been split into 3 services:
- Orchestrator: This service is in charge of getting request from the UI, save the request in a state machine to keep track of the status, and send a command message. Once the command service has finished processing the request, it will consume that message and update the status on the state machine.
- Command service: The command service is responsible for consuming the commands published by the Orchestrator. It will need to validate and process the commands and then publish any successful or failure events.
- Query service: This service is responsible for consuming the events publish by the command service and update the database. In this case, the database works just as a materialized view of the data. The source of truth will be the event store (in this case, it was Apache Kafka).
Concerns
I have mentioned above the benefits of working with Event Sourcing and CQRS but I would like to focus now on the issues that I have experienced working with this architecture.
Complexity
The main problem I found with this architecture is an increase in the level of complexity:
- More code to maintain: Now you have 3 services instead of 1 working with the same domain.
- Versioning: Handling event schema changes in an Event Sourcing architecture is not easy. More about this below.
- Error handling: Each service needs to handle possible errors. Mishandling or not handling errors could result in a corrupt state.
- Side Effect: Recovering from corrupt states is very hard and may require manually intervention.
- Testing: Each service should cover any interaction with other services, which means an increase of Unit tests, Integration test, Contract tests, and End-to-End tests.
- Eventually consistency: The command will send an event completed before the view service will write to the database. Therefore, the UI could query the view service before the data is in the database.
- Team: I was very lucky to work with the best devs in town but not every developer is familiar with Event Sourcing and CQRS and that could be a problem.
- External systems: Need to make sure that every interaction with a 3rd party is recorded as an event.
- Debugging: As in any Event-Driven architecture, following the flow of the system is much harder.
Versioning
One of the benefits of Event Sourcing is that by replaying your events you can reproduce the state of your application. Maintaining a system that can process events that were created years ago is hard. Your application keeps evolving and the schema of your events will need to evolve too.
There are basically 3 types of event schema changes:
- Backward-compatible: An example of backward-compatible change would be adding a new nullable field. Backward compatible changes are easy to deal with and you can just create a new version of the same event.
- Forward-compatible: Forward compatibility means that your new schema could be read from consumers using the old schema. Although, the consumers may not be able to use the new changes. Examples of forward-compatible changes are adding a non-nullable field or deleting optional fields.
- Full compatible: They are both Backward and Forward compatible changes. Therefore, old data can be read with the new schema, and new data can also be read with the last schema. Examples of Full compatible changes are adding or deleting optional fields.
Forward-compatible changes are much harder because usually involves migrating your old events into new ones. There are different techniques to do this kind of migration but they usually take time, especially, if you already have a system in production processing the old events.
Money
The project that I was working on was developed using Java + Spring Boot and many of their dependencies (Security, Cloud, Streams, Sleuth…). The memory consumption of JVM and Spring was too high, even when the application was doing nothing.
With the architecture described above, now you have 3 times the amount of services. In my case, it was also replicated in 5 environments so the amount of money spent in AWS each month was exorbitant.
If you have developed your application in another language which has a lower memory consumption, this will probably won’t affect you. Still, you will need to consider it because it could risk the viability of the project.
Summary
In this post, I have focused on the challenges that I have experienced working with Event Sourcing and CQRS. Event Sourcing and CQRS are very useful patterns and like any other pattern, they won’t apply in all cases.
I, personally, really like Event Sourcing. I think it is a very powerful pattern, especially when you are working with financial data. If you need a complete audit trail of all the interactions in your system, I think you need to strongly consider applying Event Sourcing.
On the other hand, I would only recommend using CQRS in a few cases. CQRS has good benefits but the increase in the level of complexity could have an impact on the productivity of the team. Personally, I would only apply CQRS when you really need to scale independently your update operations from your read operations.
References:
CQRS by Martin fowler
Event Sourcing by Martin Fowler
Event sourcing by microservices.io
Versioning of Events in Event Sourced Systems
Schema Evolution by Confluent
Acknowledgements:
Special thanks to Michael Vogiatzis and Martin Borisov who read this article and gave me feedback on how to improve it.


Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.info/register?ref=QCGZMHR6
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.info/register?ref=IHJUI7TF
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.info/register?ref=IXBIAFVY
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your article helped me a lot, is there any more related content? Thanks!
I was able to find good information from your blog articles.
My site … yt mp3 (Kelli)